
Natural Language Processing
Das Natural Language Processing (kurz NLP) wird dazu verwendet natürliche Sprache maschinell zu verarbeiten. Im Zuge der Entwicklung künstlich intelligenter Systeme und Sprachassistenten sowie Chatbots hat das NLP stark an Bedeutung gewonnen.
Die Herausforderung natürlicher Sprache ist die Unstrukturiertheit und Unbestimmtheit mit der sie in einen maschinellen Verarbeitungsprozess eingeht. Das NLP ist dazu da eine Struktur für die automatisierte Verarbeitung zu generieren.
NLP verwendet maschinelle Lernverfahren, wie supervised, unsupervised und reinforcement Learning, um auf Basis statistischer Modelle Inhalt und Struktur von Texten zu erkennen.
NLP Aufbau & Funktion - Ablauf eines NLP-Verfahrens
Das Natural Language Processing verläuft in der Regel in mehreren Phasen. Diese können grob in die Schritte Datenbereitstellung, Datenvorbereitung, Textanalyse und Textanreicherung unterteilt werden.
Die Abbildung zeigt auf der linken Seite (blau) in grober Form einen typischen Ablauf eines NLP-Verfahrens. Auf der rechten Seite (grün) ist die exemplarische Verarbeitung dargestellt. Ausgangsbasis sind immer natürlich sprachliche Texte oder Textdokumente, diese können auch aus einer Speech-to-Text Vorverarbeitung stammen.
Darüber hinaus wird ein Sprachmodell zur Verarbeitung der Texte benötigt, dieses ist in der Abbildung nicht zu sehen, es ist jedoch ein Hauptbestandteil des Verfahrens. Ein Sprachmodell ist ein Korpus an Textdokumenten mit dem das Modell trainiert wurde (maschinelles Lernen), um Regeln und Muster aus der Sprache abzuleiten.
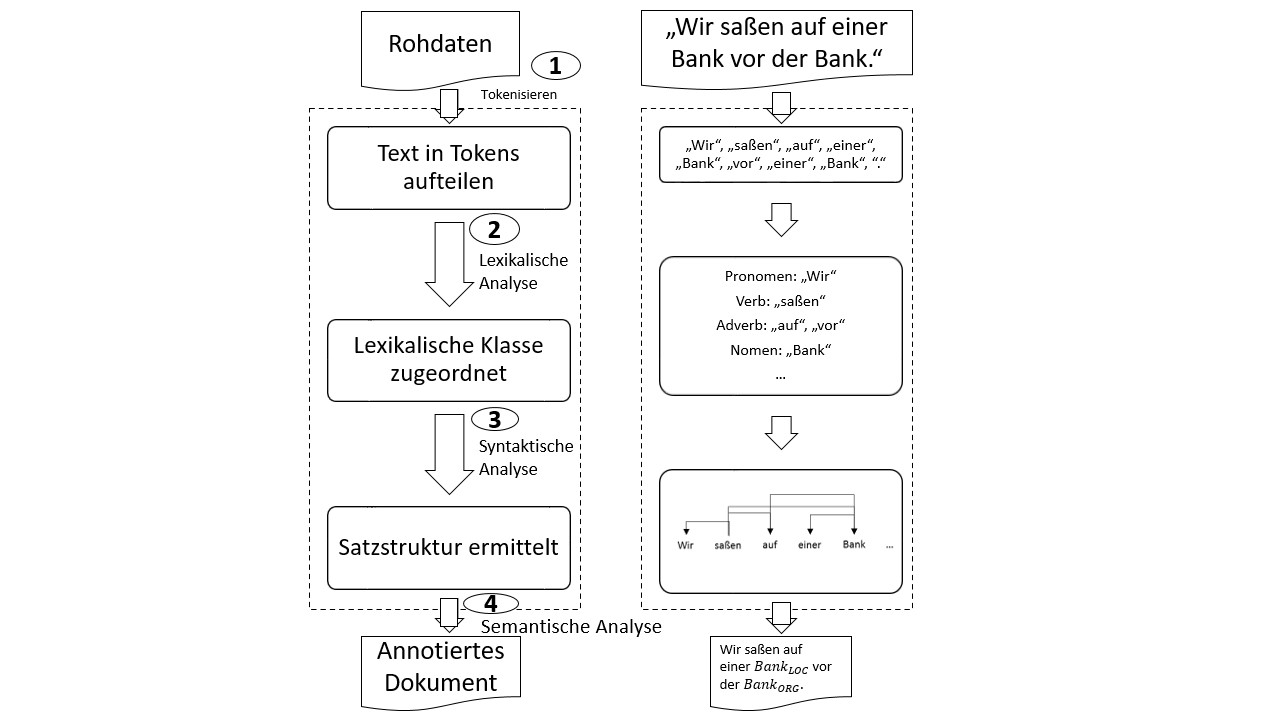
Wie die Abbildung zeigt, werden die Rohdaten zunächst mit Hilfe eines Tokenizers (1) in Segmente unterteilt. Segmente können Abschnitte, Sätze oder einzelne Wörter sein. Anschließend erfolgt in einem zweiten Schritt eine lexikalische Analyse (2), bei der Wortstämme gebildet (Stemmen, Lemmatisieren) und die lexikalische Klasse ermittelt werden. Eine lexikalische Klasse weist den Wörtern und Satzbestandteilen eine Wortart zu (siehe Beispiel rechts in der Abbildung). Auf Basis der lexikalischen Analyse kann die Satzstruktur mittels syntaktischer Analyse (3) ermittelt werden. Wie im Beispiel rechts zu sehen, werden dadurch die Wortbezüge erkannt.
In einem letzten Schritt, der semantischen Analyse (4), werden Entitäten im Text gesucht und entsprechend markiert. Bei Entitäten handelt es sich um Eigennamen die Orte, Organisationen, Personen usw. beschreiben und mittels Named-Entity-Recognition erkannt werden. Das Ergebnis eines Natural Language Processing ist ein annotiertes Dokument, das den Text strukturiert und einzelne Bestandteile über die Metadatenbeschreibung (die Annotation) bereitstellen kann.
Herausforderungen und Einsatzbereiche des Natural Language Processing
Der Erfolg, die Zuverlässigkeit und die Qualität der Textverarbeitung hängt von den Ausgangsdokumenten und dem verwendeten Sprachmodell ab. Grammatikalische und syntaktische Fehler im zu analysierenden Dokument wird die Analyse erschweren oder unmöglich machen. Ein Sprachmodell, das die Eigenheiten (z. B. medizinische Fachbegriffe) eines zu analysierenden Textes nicht kennt, ist nicht repräsentativ und kann keine Bezüge im Text herstellen, was wiederrum zu schlechten Ergebnissen bei der Sprachanalyse führt.
Wie eingangs erwähnt, wird NLP in digitalen Sprachassistenten und Chatbots eingesetzt. Dabei werden die textuellen Eingaben des Nutzers entgegengenommen, analysiert und textuelle Ergebnisse aber auch gesprochene Sprache präsentiert.
Zudem ist NLP ein wesentlicher Bestandteil der maschinellen Übersetzung (Sprachübersetzung). Es ermöglicht aber auch die Erstellung von Textzusammenfassungen (Kernaussagen eines Dokuments) etwa beim Einsatz von Text Mining und wird im Rahmen der Sentiment Analysis (Stimmungs- und Meinungsanalyse) eingesetzt.
Natural Language Processing - Vorteile und Nachteile
Die Analyse von natürlicher Sprache bringt zahlreiche Vorteile mit sich, birgt jedoch auch einige Herausforderungen.
Vorteile von Natural Language Processing
- Automatisierung von Prozessen: NLP ermöglicht es, repetitive Aufgaben wie das Analysieren von Kundenanfragen oder das Sortieren von E-Mails automatisch durchzuführen.
- Verbesserte Kommunikation: Chatbots und virtuelle Assistenten wie Siri oder Alexa bieten Nutzern schnelle und einfache Interaktionen.
- Effizienzsteigerung: Große Datenmengen, wie Kundendaten oder wissenschaftliche Texte, können in kürzester Zeit analysiert werden.
- Mehrsprachigkeit: Mit NLP lassen sich Sprachbarrieren überwinden, etwa durch Tools wie Google Translate.
Nachteile von Natural Language Processing
- Ambiguität der Sprache: Menschliche Sprache ist komplex, und Mehrdeutigkeiten sind schwer zu erkennen.
- Datenschutzprobleme: Das Verarbeiten natürlicher Sprache erfordert oft den Zugriff auf sensible Daten.
- Bias in Trainingsdaten: Wenn Modelle auf voreingenommenen Daten trainiert werden, können sie fehlerhafte oder diskriminierende Ergebnisse liefern.
Natural Language Processing - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Natural Language Processing sollte man sich folgende Punkte merken:
- Natural Language Processing ermöglicht Maschinen, menschliche Sprache zu verstehen, zu analysieren und zu generieren.
- NLP kombiniert Linguistik, Statistik und maschinelles Lernen, um Sprache zu modellieren.
- Typische Anwendungen von NLP sind Chatbots, maschinelle Übersetzung und Textanalyse.
