
Graphalgorithmen
Die Besonderheit von Graphdatenbanken liegt darin, dass Informationen nicht über relationale Tabellenstrukturen verknüpft, sondern mittels Graphen vernetzt sind. Die Knoten und Kanten von Graphen können dabei komplexe und weitreichende Informationsgeflechte darstellen.
Um die Daten abzurufen bzw. auszuwerten, sind spezielle Algorithmen, sogenannte Graphalgorithmen, notwendig.
Zwei der bekanntesten Graphalgorithmen sind die Breitensuche (breadth-first search, BFS) und die Tiefensuche (depth-first search, DFS).
Einer der bekanntesten Graphalgorithmen ist der "PageRank" von Google, um die Qualität einer Website festzulegen.
Breitensuche - Aufbau und Eigenschaften
Bei der Breitensuche werden zunächst alle Knoten, die direkt mit dem Ausgangsknoten verbunden sind, durchlaufen.
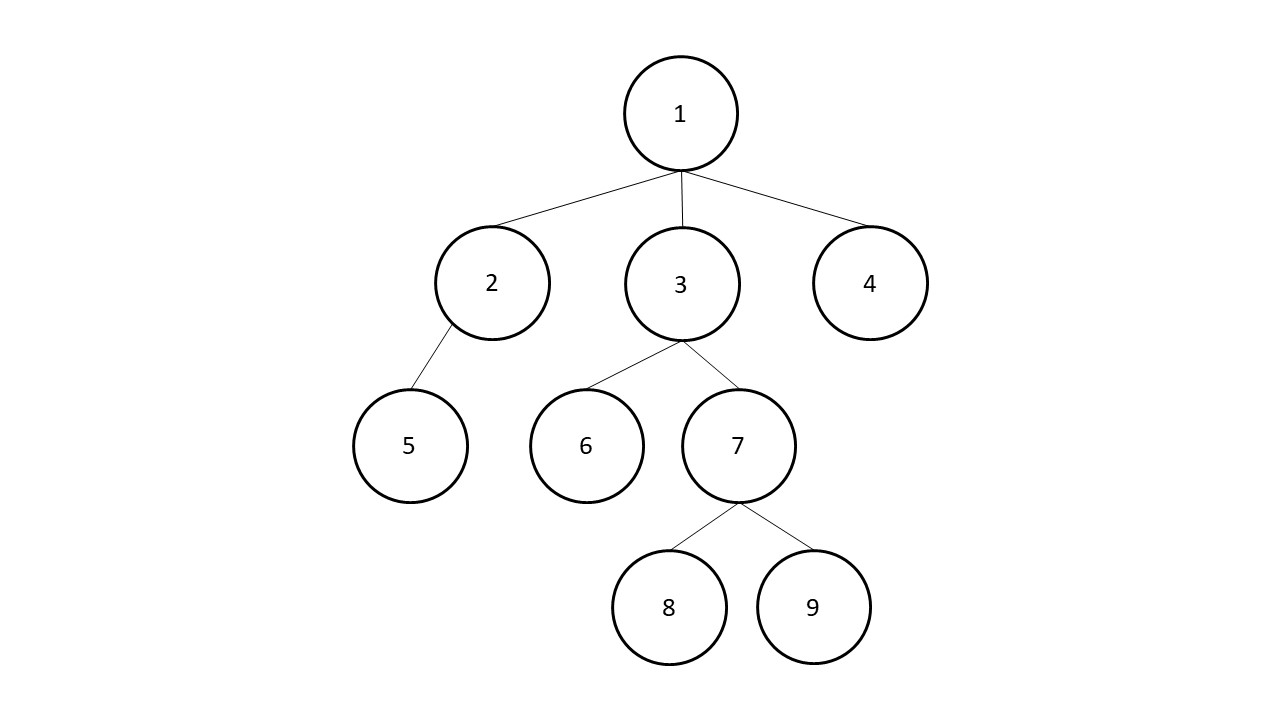
Dabei werden die Ebenen oder Schichten des Graphen nacheinander abgearbeitet, bis der Knoten mit der gesuchten Information erreicht wurde oder kein Knoten mehr übrig ist.
Mit der Breitensuche werden zunächst alle erreichbaren Knoten ermittelt und am Ende einer Liste eingefügt.
Anschließend wird diese Liste abgearbeitet bis das gesuchte Element gefunden wurde oder die Liste keine weiteren Knoten enthält.
Breitensuche - Beispielmodell

Die Breitensuche benötigt relativ viel Speicherplatz, da sich der Algorithmus alle gefundenen Knoten merkt, um diese sukzessive abzuarbeiten. Im schlechtesten Fall müssen alle Knoten gesucht und verarbeitet werden. Das führt bei großen Graphen zu einer langen Laufzeit. Das Verfahren ist vollständig und liefert immer ein Element zurück, wenn es im Graph existiert.
Tiefensuche - Aufbau und Eigenschaften
Das Vorgehen bei der Tiefensuche unterscheidet sich von dem der Breitensuche. Hier werden zunächst alle Knoten entlang eines Pfades untersucht – daher auch die Bezeichnung Tiefensuche.
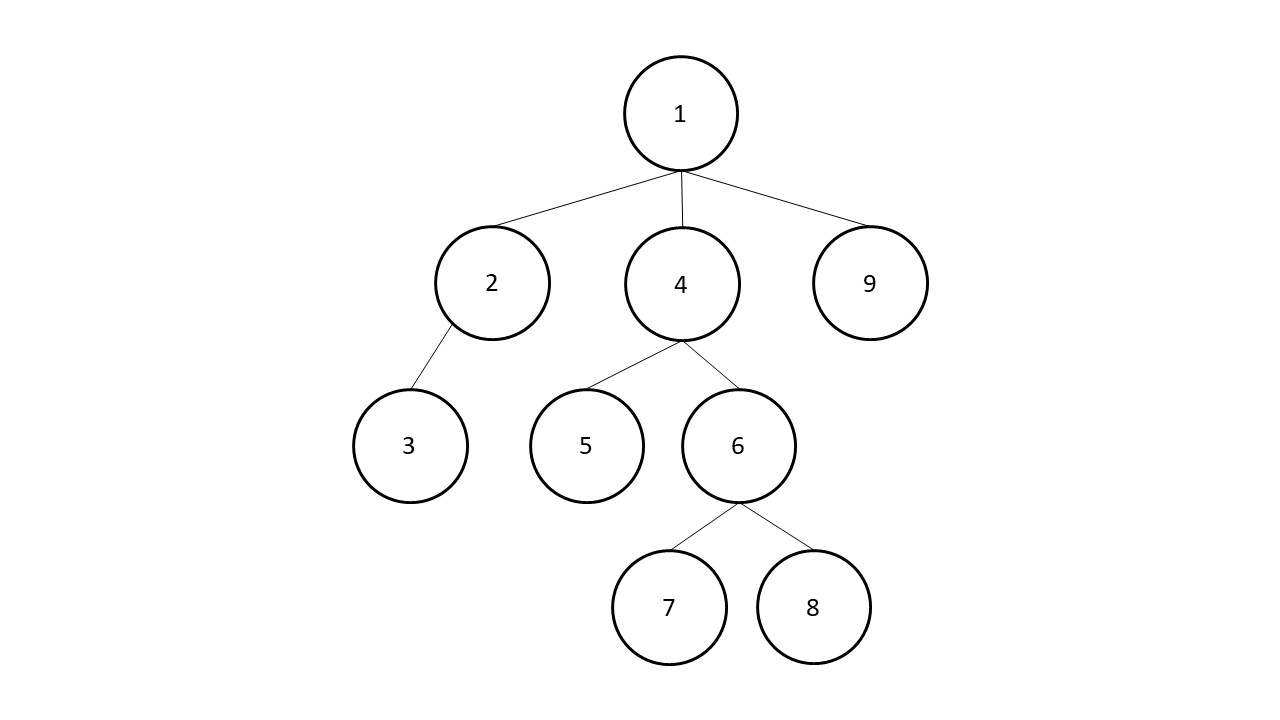
Wurde der Graph entlang eines Pfades von oben nach unten durchlaufen und das gesuchte Element nicht gefunden, wird ein anderer Pfad ausgewählt.
Welche Knoten zuerst durchlaufen werden, hängt von der Realisierung des Graphs ab. Dieser kann bspw. als verkettete Liste, Inzidenzmatrix oder als Adjazenzmatrix implementiert werden.
Tiefensuche - Beispielmodell
Auch bei der Tiefensuche wird zunächst ein Startknoten ausgewählt. Von diesem aus werden alle kleineren Nachfolgeknoten ermittelt und der Reihe nach in einem Stack gespeichert.
Dieser wird abgearbeitet bis es keine Nachfolger mehr gibt. Anschließend wird der Knoten aus dem Stack entfernt.
Der Algorithmus sucht nach weiteren noch nicht besuchten Knoten und bewegt sich entlang deren Pfade bis das Element gefunden wurde oder kein unbesuchter Knoten mehr erreichbar ist.
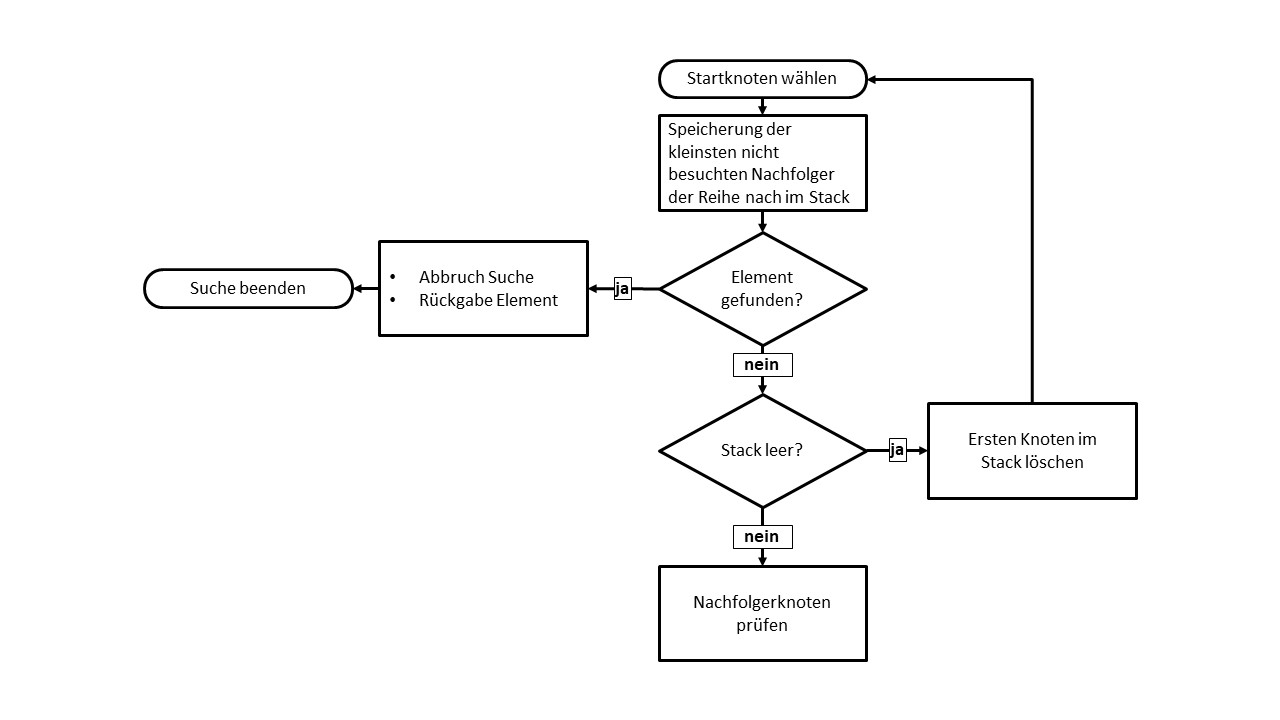
Die Tiefensuche ist nicht vollständig, das heißt es kann der Fall eintreten, dass ein existierendes Element z.B. aufgrund eines Zyklus nicht gefunden wird. Der Speicherplatzbedarf hängt von der Implementierung ab.
Graphalgorithmen - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Graphalgorithmen sollte man sich folgende Punkte merken:
- Graphalgorithmen werden für das Abrufen und Auswerten von Daten in einer Graphdatenbank verwendet.
- Zwei der bekanntesten Graphalgorithmen sind die Breitensuche (breadth-first search,BFS) und die Tiefensuche (depth-first search, DFS).
- Einer der bekanntesten Graphalgorithmen ist der "PageRank" von Google, um die Qualität einer Website festzulegen.
