
Apache Pig
Apache Pig wurde 2006 von Yahoo entwickelt und ist heute ein Apache Open Source-Projekt sowie Bestandteil des Hadoop Ökosystems.
Anlass der Entwicklung waren die Komplexität und die Schwierigkeiten bei der Programmierung von MapReduce Verfahren in Java, zur Abfrage und Analyse großer, verteilter Datenbestände, sowie deren starke Fixierung auf den entwickelten Datenfluss.
Bei Pig handelt es sich um eine erweiterbare Skriptsprachen Plattform, die eine Abfrageoptimierung enthält und einfach zu programmieren ist. Es werden keine Java Kenntnisse zur Erstellung von MapRaduce-Verfahren und -Transformationen benötigt.
Apache Pig - Systemarchitektur und Komponenten
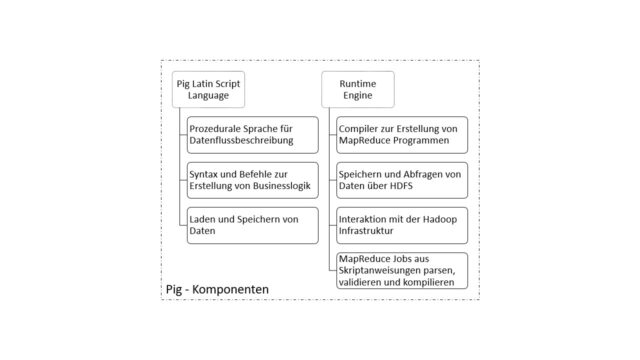
Pig lässt sich in die zwei wesentliche Komponenten Pig Latin Script Language (kurz Pig Latin) und Runtime Engine aufteilen (siehe Abbildung). Pig Latin ist die Schnittstelle zum Nutzenden und stellt eine prozedurale Sprache zur Beschreibung von Datenflüssen zur Verfügung, deren Syntax und Befehle zur Erstellung von Businesslogiken verwendet werden kann. Mit Pig Latin lassen sich Daten einfach aus Dateien laden und in Hadoop speichern sowie Abfragen erstellen.
Apache Pig - Ablauf einer Skriptausführung
Die Runtime Engine transformiert die mit Pig Latin erstellten Skripte in MapReduce Anweisungen und Programme und optimiert die Ausführung selbstständig. Darüber hinaus ist die Runtime Engine für die Interaktion mit der Hadoop Infrastruktur zuständig und gibt dem Nutzenden die Ergebnisse der Ausführung zurück. In der Abbildung sind die Teilkomponenten der Runtime Umgebung zu sehen:
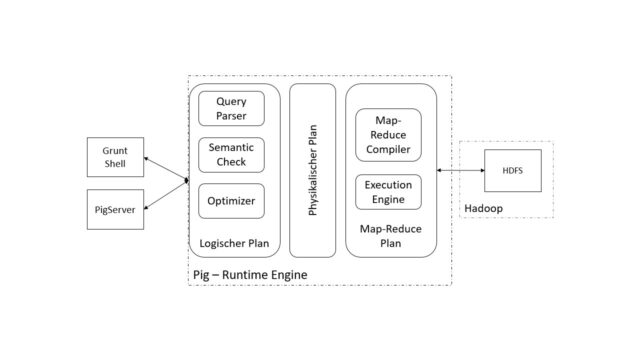
Der Ablauf in Pig erfolgt in drei Phasen.
Phase 1: Skripterstellung und Ausführungsplan initialisieren
Zunächst werden die zu verarbeitenden Daten mittels Pig Latin geladen und ein Ausführungsskript erstellt. Nachdem der Nutzende sein Skript über die Grunt Shell oder den PigServer geschrieben hat, wird dieses an die Pig Runtime Engine übergeben.
Das Skript beschreibt den logischen Zusammenhang der abzufragenden Daten und muss operationalisiert werden. Dazu ist im nächsten Schritt ein logischer Ausführungsplan zu erstellen.
Phase 2: Ausführungsplan validieren und MapReduce-Plan erstellen
Das Skript wird anschließend in einzelne Anweisungen zerlegt und mit einem Parser überführt, um die Syntax und Validität zu überprüfen. Dies erfolgt über den Query Parser, der die Anfrage zur weiteren Verarbeitung strukturiert.
Es folgen die semantische Prüfung und die Optimierung des Plans. Sind diese Schritte erfolgreich durchlaufen, wird aus dem logischen Plan ein physikalischer Plan erstellt, der die Speicherung der Daten berücksichtigt. Aus dem physikalischen Plan wird mittels MapReduce-Compiler ein ausführbarer MapReduce-Plan generiert und der Execution Engine übergeben.
Phase 3: MapReduce-Plan ausführen und Ergebnisse ablegen
Die Ausführung erfolgt anschließend, je nach Abhängigkeit der Daten und Aufbau des Map-Reduce Plans, schrittweise oder als Ganzes durch Hadoop. Die Ergebnisse werden visuell an den Nutzenden zurückgegeben oder im HDFS Dateisystem zur weiteren Verarbeitung oder späteren Analyse gespeichert.
Pig Datenmodell
Das Pig Datenmodell sieht die vier Basistypen Atom, Tuple, Bag und Map vor, in denen die Daten gespeichert und verwaltet werden:
- Atom: Dieser Typ enthält einen atomaren Wert wie z. B. „Mustermann“.
- Tuple: Ein Tuple beschreibt eine Sequenz von Feldern, die einen beliebigen Datentyp (z. B. String, Integer, Date) annehmen können. Ein Beispiel wäre („Max“, „Mustermann“, 35).
- Bag: Ein Bag ist eine Sammlung an Tupeln, mit beliebig verschiedenen und verschachtelten Strukturen, wie Beispielsweise {(„Max“), („Maxima“, (35, 30))}.
- Map: Die Map beschreibt ein assoziatives Array und besitzt einen Key-Value Aufbau, bei dem ein Key nur einmalig enthalten sein darf. Der Key muss ein Chararray sein, der Value kann jeden beliebigen Datentyp annehmen. Beispiel: [name#Max,age#35].
Apache Pig - Vorteile und Nachteile
Die Nutzung von Apache Pig bietet sowohl Vor- als auch Nachteile, die von den spezifischen Anforderungen des Projekts abhängen.
Apache Pig - Vorteile von Apache Pig
Die folgenden Vorteile machen Apache Pig zu einer attraktiven Wahl für viele Anwendungsfälle:
- Benutzerfreundlichkeit: Pig Latin ist einfacher zu erlernen und zu verwenden als Java-basierte MapReduce-Programmierung.
- Flexibilität: Es unterstützt eine Vielzahl von Datenquellen und Ausgabeformaten.
- Effizienz: Durch die automatische Optimierung von Pig Latin-Skripten wird die Leistung der Datenverarbeitung maximiert.
- Wiederverwendbarkeit: Skripte sind modular aufgebaut und können leicht wiederverwendet werden.
Apache Pig - Nachteile von Apache Pig
Trotz der vielen Vorteile gibt es auch einige Einschränkungen:
- Eingeschränkte Echtzeitfähigkeit: Apache Pig ist primär für Batch-Verarbeitung ausgelegt und weniger geeignet für Echtzeitanalysen.
- Abhängigkeit von Hadoop: Es kann nur in Hadoop-Umgebungen verwendet werden, was die Flexibilität einschränkt.
- Komplexität bei sehr großen Workflows: Bei umfangreichen Workflows können die Pig Latin-Skripte unübersichtlich werden.
Apache Pig - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Apache Pig sollte man sich folgende Punkte merken:
- Apage Pig vereinfacht die Arbeit mit Daten in Hadoop-Umgebungen.
- Apache Pig bietet eine gut Flexibilität und Effizienz.
- Apache Pig fehlt es zum Teil an der Echtzeitfähigkeit.
