
Apache Hive
Apache Hive ist eine Open Source Lösung zur Erstellung von ETL Prozessen und Data Warehouse Lösungen, die auf Hadoop aufsetzt.
Hive gehört zu den Top-Level Projekten der Apache Software Foundation. Die ursprüngliche Entwicklung begann mit Apache Hadoop.
Sowohl Hive als auch Hadoop sind für die Verarbeitung und Abfrage sehr großer Datenmengen auf verteilten Speichersystemen entwickelt wurden. Hive und Hadoop haben somit große Relevanz für den Einsatz im Big Data Umfeld. Beide sind für die Verarbeitung großer unstrukturierter Datenmengen ausgelegt.
Dabei eignet sich Hive nicht für transaktionale Anwendungen, was typisch für Data Warehouse Lösungen ist, da die Aufbereitung, Speicherung und Analyse der Daten im Vordergrund stehen. Anders als bei relationalen Data Warehouse Datenbanken werden in Hive keine festen Schemata und Datentypen für die Speicherung der Daten festgelegt.
Dadurch können die anfallenden Daten zunächst gespeichert werden und gehen in der Verarbeitung nicht verloren. Der Nachteil darin ist, dass die Abfrage von Daten sehr lange dauern kann, da die Informationen aufwändig gesucht werden müssen.
Systemarchitektur und Komponenten
Für die Speicherung und Anfrageverarbeitung nutzt Hive das verteilte Speichersystem HDFS von Hadoop. Für die Verarbeitung der Daten ist ein Zusammenspiel verschiedener Komponenten (siehe Abbildung) notwendig. Ausgehend vom Client werden Anfragen an Hive gestellt, die von den Systemkomponenten aufbereitet und anschließend als Abfragen an das Datenverwaltungssystem (Hadoop) geschickt werden. Die wichtigsten Komponenten werden nachfolgend kurz beschrieben.
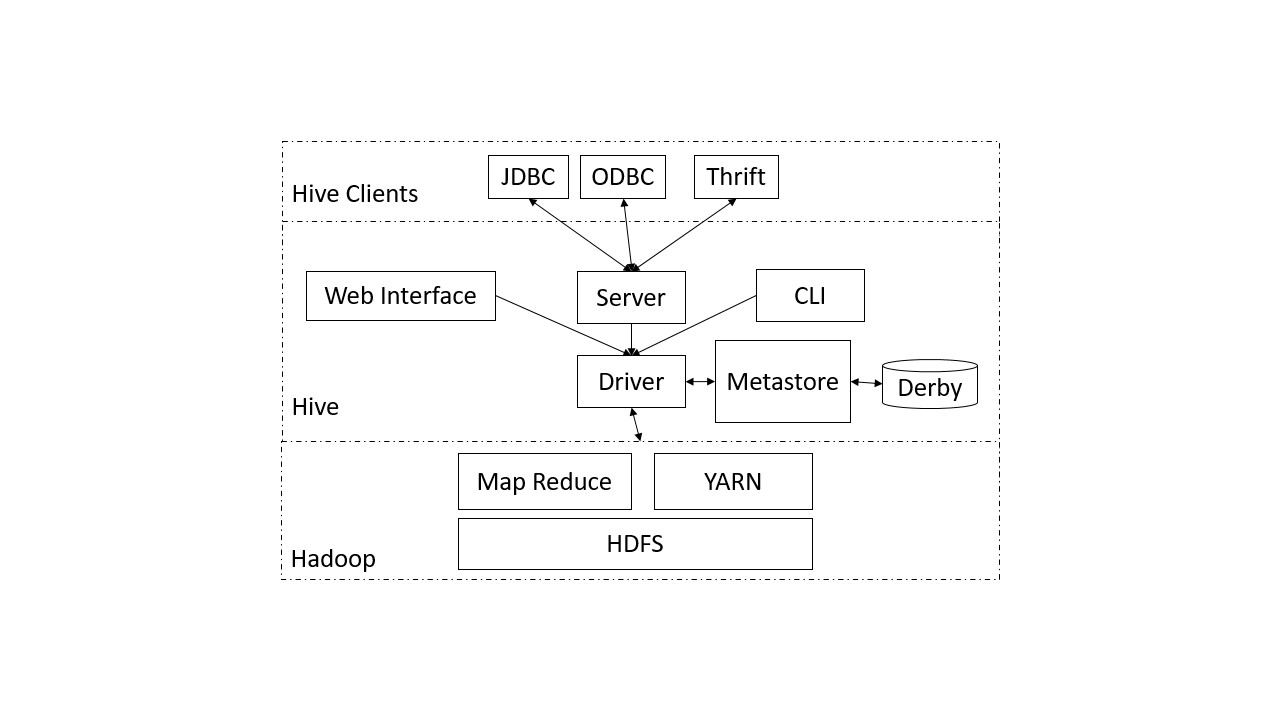
Hive Clients
Hive kann durch verschiedene Client Applikationen genutzt werden. Hierfür stehen die Standardtreiber JDBC und ODBC zur Verfügung, die in den Applikationen genutzt werden müssen, um Daten über Hive zu laden und abzufragen. Darüber hinaus besteht die Möglichkeit einen Thrift Client zu verwenden. Der Hive Server basiert auf Thrift, bei dem es sich um ein Kommunikationsprotokoll der Apache Software Foundation handelt. Alle von Thrift unterstützten Programmiersprachen (z. B. Jave, Objective-C, PHP, Python usw.) können in einem Client genutzt werden, um die API zu integrieren.
CLI – Command Line Interface
Das Command Line Interface ist die Standard-Shell von Hive, mit dem Abfragen und Kommandos direkt ausgeführt werden können. Das CLI wird über einen Hive Service bereitgestellt.
Web Interface
Bei dem Web Interface handelt es sich ebenfalls um einen Service von Hive. Anders als beim CLI steht eine grafische Benutzeroberfläche zur Erstellung und Ausführung von Abfragen zur Verfügung.
Metastore
Der Metastore stellt das zentrale Repository der Hive Metadaten dar. Darin enthalten sind Metadaten zu Tabellen, mit deren Schema und Speicherort, sowie angelegte Partitionen im System. Partitionen sind vergleichbar mit dichten Indizes auf Spalten und werden als Verzeichnisstruktur angelegt. Der Metastore selbst ist standardmäßig in einer relationalen Derby Datenbank gespeichert, die unabhängig vom HDFS Dateisystem betrieben wird. Der Zugriff erfolgt über eine Service API durch die ein Zugriff auf die Informationen ermöglicht wird.
Hive Driver
Der Hive Driver ist eine zentrale Komponente und besteht aus dem Compiler, dem Optimizer und dem Executor. Die Abbildung zeigt den Ablauf einer Abfrageverarbeitung:
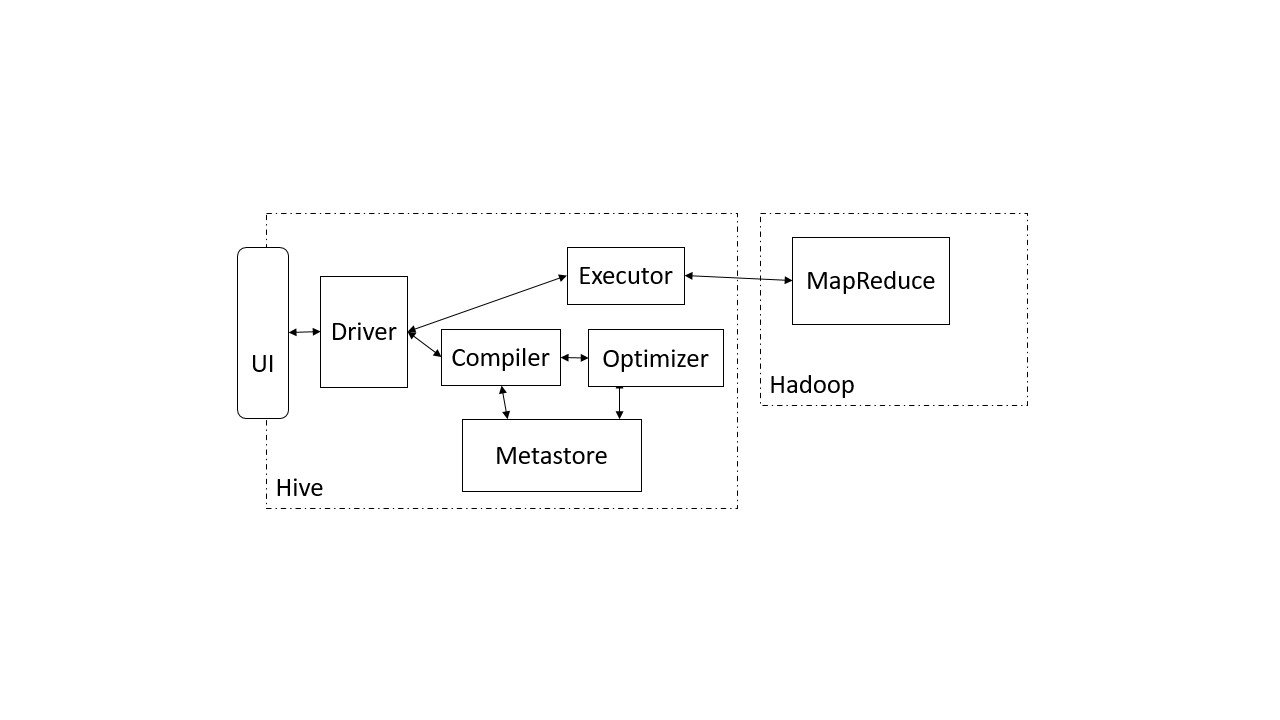
Der Driver nimmt die Anfrage entgegen und leitet diese zunächst an den Compiler weiter. Dieser prüft die Abfrage mit Hilfe der Informationen aus dem Metastore zur Überprüfung der Datentypen und der semantischen Analyse. Der Optimizer erstellt auf Basis der Analyse einen Ausführungsplan in Form eines gerichteten Graphen für das MapReduce Verfahren in Hadoop. Anschließend wird der Ausführungsplan kompiliert und dem Executor zur Verfügung gestellt. Dieser führt den Plan unter Berücksichtigung der Abhängigkeiten in einzelnen Schritten durch.
Hive Query Language
Hive stellt eine eigene SQL-ähnliche Abfragesprache - namens HiveQL (Hive Query Language) – zur Verfügung, durch die Anfragen automatisch in MapReduce Verarbeitungen auf Hadoop übersetzt werden. Die HiveQL abstrahiert von der durch Java-APIs bereitgestellten Schnittstellen zu Hadoop.
HiveQL hält sich nicht vollständig an den Standard SQL-92 für SQL-Abfragesprache und weist einige Besonderheiten auf. So ermöglicht sie beispielsweise das Einfügen von Daten in mehrere Tabellen gleichzeitig. Erst ab der Version 0.14 werden wichtige Funktionen zum Einhalten des ACID-Prinzips unterstützt.
Apache Hive - Vorteile und Nachteile
Die Nutzung von Apache Hive bietet verschiedene Vor- und Nachteile, die je nach Anwendungsfall abgewogen werden müssen.
Apache Hive - Vorteile von Apache Hive
- SQL-ähnliche Syntax: HiveQL macht es für SQL-erfahrene Benutzer leicht, sich in Hive einzuarbeiten.
- Skalierbarkeit: Kann enorme Datenmengen in Hadoop-Umgebungen verarbeiten.
- Flexibilität: Unterstützt verschiedene Datenspeicherformate wie ORC, Parquet und Avro.
- Automatisierung: Vereinfacht ETL-Prozesse durch standardisierte Workflows.
Apache Hive - Nachteile von Apache Hive
- Eingeschränkte Echtzeitfähigkeit: Hive ist für Batch-Verarbeitung ausgelegt und weniger geeignet für Echtzeitanalysen.
- Komplexität bei großen Abfragen: Die Umwandlung von HiveQL in Hadoop-Jobs kann bei sehr komplexen Abfragen ineffizient sein.
- Abhängigkeit von Hadoop: Die Leistung hängt stark von der Hadoop-Infrastruktur ab.
Apache Hive - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Apache Hive sollte man sich folgende Punkte merken:
- Apache Hive bietet eine SQL-ähnliche Abfragesprache, die speziell für Big-Data-Analysen entwickelt wurde.
- Es kann große Datenmengen in verteilten Hadoop-Umgebungen effizient verarbeiten.
- Apache Hive ist für Batch- statt Echtzeitverarbeitung optimiert.
