
Apache Cassandra
Apache Cassandra ist ein Open-Source Datenbankmanagementsystem, das zur Verarbeitung riesiger Datenmengen im Big Data Bereich eingesetzt wird.
Cassandra wurde ursprünglich von Facebook entwickelt und 2008 veröffentlicht. Seit 2010 ist es ein Projekt der Apache Foundation. Das verteilte Datenbankverwaltungssystem zählt zu den spaltenorientierten NoSQL Datenbanken. Es basiert auf Java.
Seit 2011 gibt es die Abfragesprache Cassandra Query Language (CQL). Der Aufbau der Syntax und die enthaltenen Keywords erinnern stark an SQL. Die Abfrage von Daten erfolgt in gleicher Weise wie bei SQL. CQL besitzt einen Abstraction-Layer der die Implementierungsdetails verbirgt.
Apache Cassandra - Aufbau und Struktur
Die Struktur von Apache Cassandra basiert auf einer verteilten Architektur ohne zentralen Punkt der Steuerung. Die wichtigsten Merkmale sind:
- Cluster-basierte Architektur: Daten werden auf mehrere Knoten (Nodes) verteilt, die zusammen einen Cluster bilden.
- Peer-to-Peer-Modell: Jeder Knoten im Cluster ist gleichberechtigt, was die Ausfallsicherheit erhöht.
- Keyspace und Column Families: Cassandra verwendet Keyspaces (vergleichbar mit Datenbanken) und Column Families (vergleichbar mit Tabellen), um Daten zu organisieren.
- Replikation: Daten werden automatisch über mehrere Knoten repliziert, um Datenverluste zu vermeiden.
- Consistent Hashing: Ermöglicht eine effiziente Verteilung der Daten und eine einfache Skalierung des Systems.
Datenorganisation in Nodes
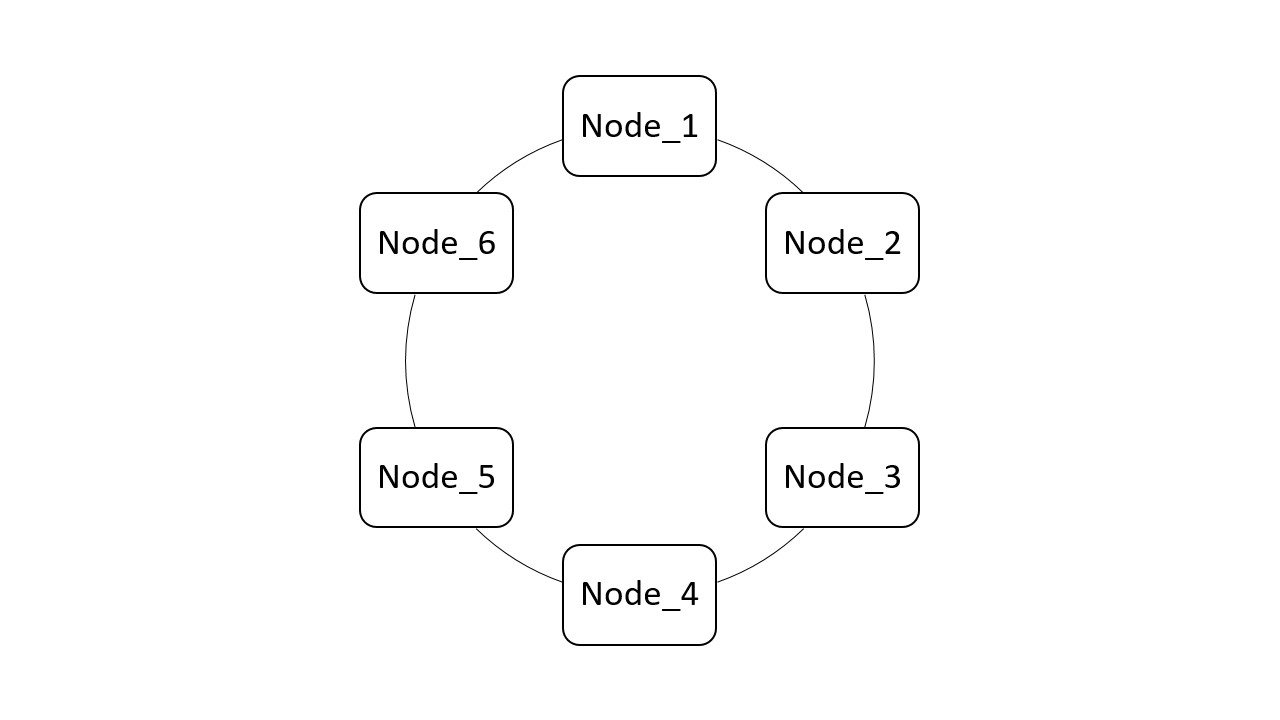
Cassandra organisiert Daten auf sogenannten Nodes, die, wie in der Abbildung zu sehen, in einem Ring ohne einen zentralen Master angeordnet sind. Die kleinste Anzahl an Nodes kann eins betragen. Kommen neuen Nodes hinzu, werden die Daten auf alle Knoten verteilt, inklusive Repliken, die eine Ausfallsicherheit gewährleisten sollen.
Der Ring verfügt über eine sogenannte Tokenrange. Jedem Node im Ring wird ein Teil der Tokenrange zugeteilt. Neuen Nodes wird ein Teil der Tokenrange vom benachbarten Node inklusive der bereits vorhandenen Daten übertragen. Die Nodes übernehmen die Datensätze, deren Wert in die ihm zugeteilte Tokenrange fällt. Die Verteilung von Daten erfolgt über den mit einem Hash-Algorithmus berechneten Primärschlüssel jedes einzelnen Datensatzes.
Clustering mit Datacenter
Zur besseren Lastverteilung und Ausfallsicherheit gibt es sogenannte virtuelle Nodes auf denen die Daten stärker gestreut werden. Dadurch können Nodes ohne Downtime ausgetauscht werden. Die Organisation der Nodes findet in Clustern statt. Diese können, wie in Abbildung zu sehen, über zwei Ebenen strukturiert werden.
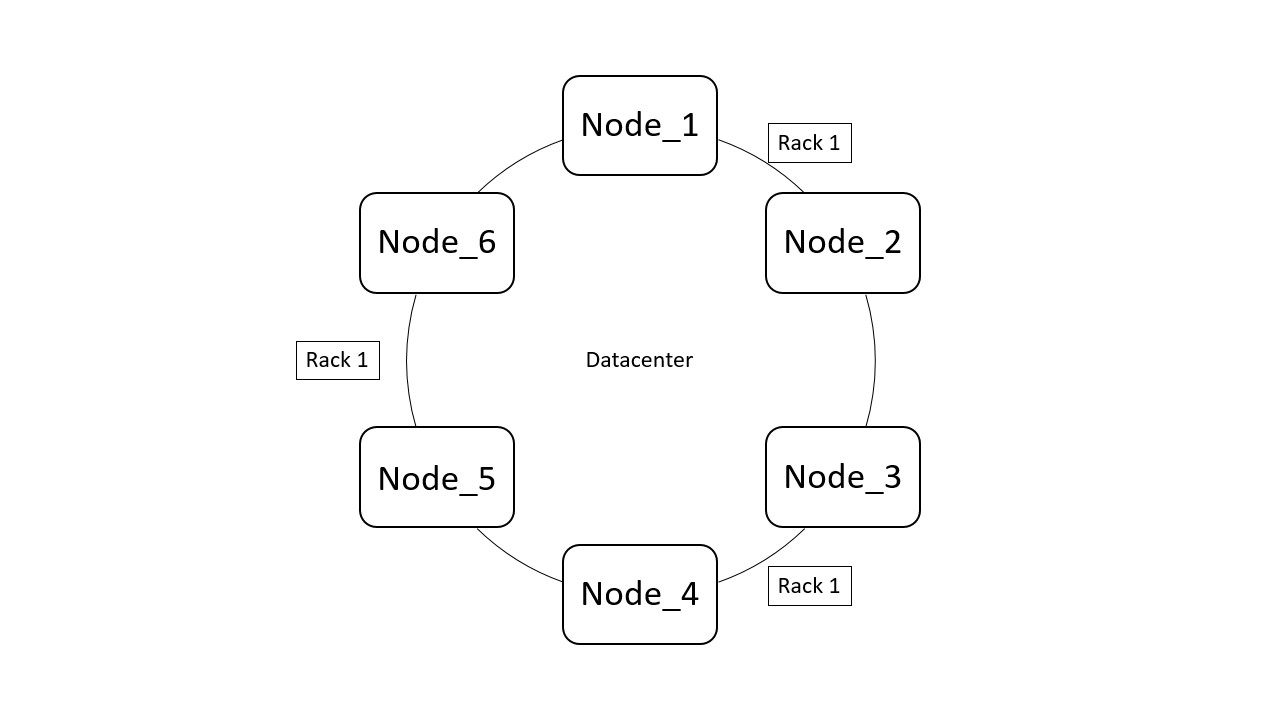
Auf der obersten Ebene steht das Datacenter (Abb. die Ringstruktur). Dieses kann dazu verwendet werden die Cluster auf unterschiedliche Server an unterschiedlichen Standorten aufzuteilen.
Innerhalb eines Datacenters können Racks definiert werden, diese sind in der Abbildung markiert. Nodes im gleichen Rack liegen nahe beieinander. Innerhalb des Datacenters können zusätzlich sogenannte Snitches konfiguriert werden. Durch diese werden Anfragen an nahe gelegene Nodes weitergeleitet, da die Annahme besteht, dass diese die Ergebnisse am schnellsten zurückliefern können.
Apache Cassandra - Vorteile und Nachteile
Apache Cassandra - Vorteile von Apache Cassandra
Apache Cassandra bietet eine Vielzahl von Vorteilen, die es zu einer beliebten Wahl für Unternehmen machen:
- Hohe Skalierbarkeit: Cassandra kann horizontal skaliert werden, indem einfach neue Knoten zum Cluster hinzugefügt werden.
- Hohe Verfügbarkeit: Dank der Replikation und des dezentralen Aufbaus ist das System auch bei Ausfällen einzelner Knoten sehr robust.
- Flexibles Datenmodell: Cassandra erlaubt die Speicherung von semi-strukturierten und unstrukturierten Daten.
- Schnelle Schreiboperationen: Das System ist für schnelle Schreibvorgänge optimiert.
- Globale Verteilung: Daten können über mehrere Rechenzentren hinweg verteilt werden.
Apache Cassandra - Nachteile von Apache Cassandra
Trotz seiner Stärken gibt es einige Nachteile, die bei der Nutzung von Apache Cassandra berücksichtigt werden sollten:
- Eingeschränkte Abfragemöglichkeiten: Cassandra bietet keine Möglichkeiten für komplexe SQL-Abfragen.
- Komplexität der Verwaltung: Die Einrichtung und Wartung eines Cassandra-Clusters erfordert spezialisierte Kenntnisse.
- Fehlende ACID-Unterstützung: Cassandra ist nicht für Transaktionen ausgelegt, die eine strenge Konsistenz erfordern.
- Ressourcenintensiv: Der Betrieb eines Clusters kann viel Speicherplatz und Rechenleistung beanspruchen.
Apache Cassandra - Beispiel für Apache Cassandra
Ein typisches Beispiel für die Nutzung von Apache Cassandra ist ein Echtzeitanalysesystem für Benutzerinteraktionen. Unternehmen wie Netflix und Spotify verwenden Cassandra, um riesige Datenmengen über mehrere Rechenzentren hinweg zu speichern und Benutzerdaten in Echtzeit zu analysieren.
Apache Cassandra - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Apache Cassandra sollte man sich folgende Punkte merken:
- Apache Cassandra ist eine fehlertolerante und skalierbare NoSQL-Datenbank.
- Sie bietet hohe Verfügbarkeit durch Datenreplikation und eine dezentrale Architektur.
- Cassandra ist optimiert für schnelle Schreiboperationen und globale Datenverteilung.
