
Unsupervised Learning
Das Unsupervised Learning, auch unüberwachtes Lernen genannt, ist dem Bereich des Machine Learning zuzuordnen. Neben dem Unsupervised Learning gibt es das Supervised Learning und das Reinforcement Learning, die ebenfalls Teil des Machine Learnings sind.
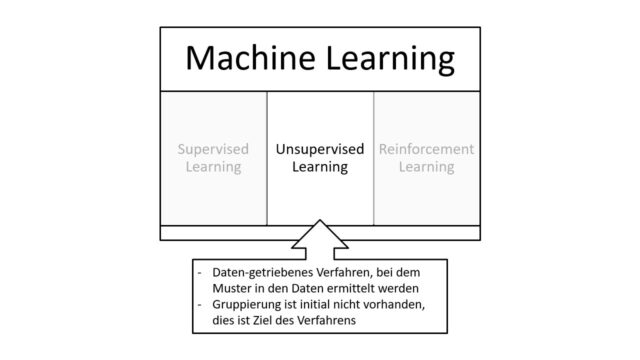
Das Unsupervised Learning ist ein daten-getriebenes Verfahren, bei dem feste Muster in den Daten ermittelt werden.
Eine Gruppierung der Daten ist im Unsupervised Learning initial nicht vorhanden. Eine Gruppierung ist das Ziel des Verfahrens.
Vorgehensweise beim Unsupervised Learning
Beim Unsupervised Learning geht es darum, die unbekannten Strukturen und Beziehungen zwischen den Daten zu ermitteln. Die Gruppierung und Aufteilung der einzelnen Datensätze ist unbekannt.
Die Algorithmen des Unsupervised Learning müssen selbstständig Strukturen, sogenannte Cluster, finden. Ziel des Lernens ist der Aufbau eines Modells, mit dessen Hilfe Daten zu den vorhandenen Clustern zugeordnet werden können. Die Anzahl und Art der Cluster ändert sich mit den zugrundeliegenden Daten des Corpus.
In der Regel schätzt ein Unsupervised Learning-Verfahren nicht nur neue Daten, sondern integriert diese in das eigene Modell. Darüber hinaus benötigen sie meist riesige Datenmengen, um ein stabiles Modell aufbauen zu können. Daher eignet es sich nicht für alle Allwendungsfälle.
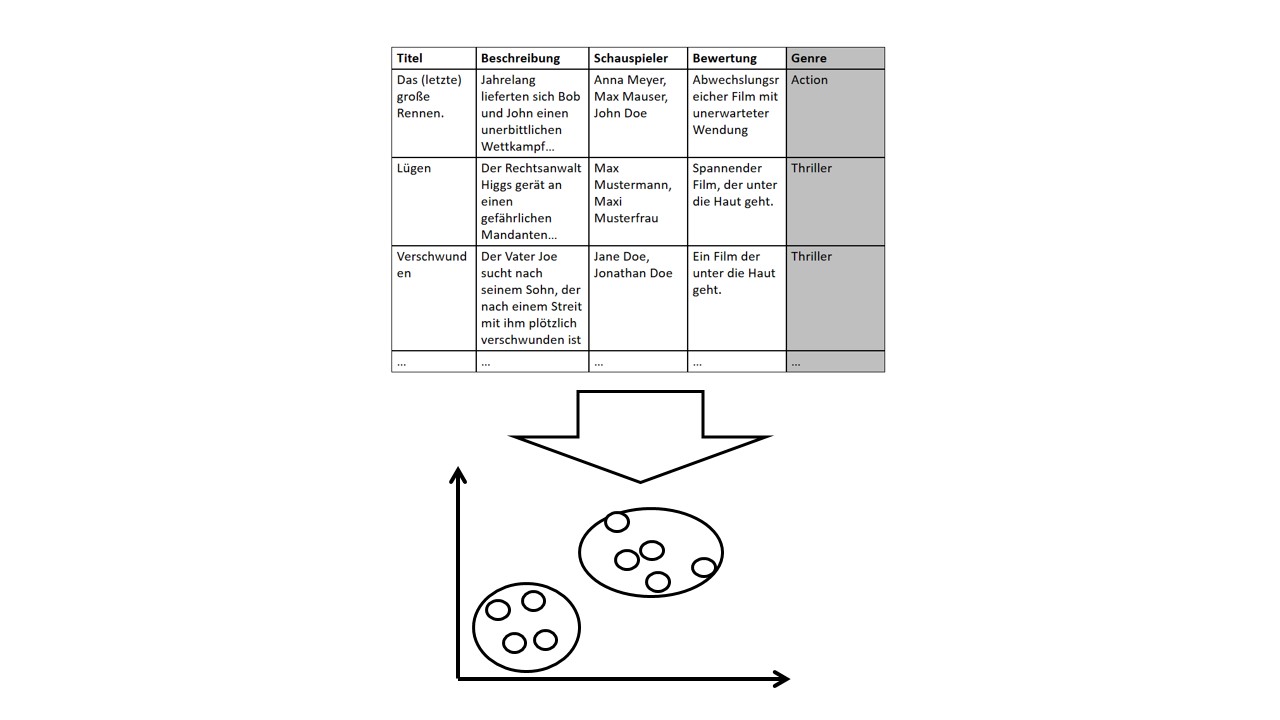
In der unten dargestellten Abbildung ist ein Corpus dargestellt, der die Feature Titel, Beschreibung, Schauspieler und Bewertung umfasst. Anders als beim Supervised Learning ist hier kein Zielwert vorgegeben. Das Verfahren muss die Datensätze selbstständig anhand der verfügbaren Informationen gruppieren. Der Output stellt eine Clusterung der Daten dar, wie exemplarische in der Abbildung zu sehen ist.
Algorithmen für Unsupervised Learning-Verfahren
Im Bereich des Unsupervised Learning wurden verschiedene Algorithmen entwickelt und erweitert. Zu den bekanntesten gehören das K-Means Clustering, das Gaussian Mixture Model und die neuronalen Netzwerke.
Einsatzbereiche für Unsupervised Learning
Anwendung finden die Unsupervised Learning-Verfahren in der Textanalyse, bei der inhaltliche und semantische Informationen extrahiert werden. Es wird oft im Rahmen von Text Mining angewandt, um die Analyse der Inhalte zu ermöglichen. Daher spielt das Unsupervised Learning-Verfahren auch in der Sprachanalyse eine große Rolle, aber auch in der automatischen Bilderkennung und -verarbeitung.
Zum Einsatz kommen die Ergebnisse in Sprachassistentsystemen oder Social Bots, die auf den Nutzenden reagieren, indem die gesprochenen oder geschriebenen Informationen automatisch analysiert werden und in ein Reaktionsverhalten einfließen.
Unsupervised Learning - Vorteile und Nachteile
Unsupervised Learning bietet zahlreiche Vorteile, bringt aber auch Herausforderungen mit sich. Die wichtigsten Aspekte sind:
Unsupervised Learning - Vorteile von Unsupervised Learning
Unsupervised Learning kann in vielen Bereichen effektiv eingesetzt werden, besonders wenn keine gelabelten Daten verfügbar sind. Zu den Vorteilen gehören:
- Flexibilität: Kann mit unklassifizierten Daten arbeiten, die oft leichter verfügbar sind.
- Entdeckung unbekannter Muster: Identifiziert neue Zusammenhänge und Trends, die mit Supervised Learning möglicherweise übersehen werden.
- Automatisierung: Reduziert manuellen Aufwand bei der Datenannotation.
Unsupervised Learning - Nachteile von Unsupervised Learning
Trotz der Vorteile gibt es einige Einschränkungen:
- Mangelnde Kontrolle: Ohne Labels kann es schwierig sein, die Ergebnisse zu validieren.
- Komplexität: Das Interpretieren der Ergebnisse erfordert oft tiefergehendes Fachwissen.
- Unvorhersehbare Ergebnisse: Algorithmen können Muster finden, die irrelevant oder unbrauchbar sind
Unsupervised Learning - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Unsupervised Learning sollte man sich folgende Punkte merken:
- Unsupervised Learning identifiziert Muster in unlabeled Daten.
- Wichtige Techniken sind Clustering und Dimensionality Reduction.
- Unsupervised Learning bietet Flexibilität, birgt jedoch Herausforderungen bei der Ergebnisvalidierung.
