
Text Mining
Das Text Mining beschäftigt sich mit der Verarbeitung und Analyse von Textdaten, um mittels linguistischer und statistischer Verfahren Muster und unbekannte Informationen aus Dokumenten oder natürlich-sprachlichen Quellen zu erschließen und für den Nutzer visuell aufzubereiten.
Die automatisierte Verarbeitung von Textdaten ist nicht trivial. Textdaten sind unstrukturiert und hochdimensional. Dies hat zur Folge, dass die Textdaten im Prozess strukturiert und die dimensionalen Ausprägungen reduziert werden müssen.
Hierfür werden Methoden der Textnormalisierung und der Dimensionsreduzierung angewendet.
Textverarbeitung im Text Mining
Das Text Mining greift auf verschiedene Verfahren der Datensuche und -verarbeitung zurück und kombiniert diese in einem Prozess der Textdatenverarbeitung und der visuellen Analyse. Verwandte und entlehnte Verfahren sind hierbei das Information Retrieval (IR) und die Information Extraction (IE). Mittels Data Mining wird nach Mustern und unbekannten Informationen sowie Zusammenhängen im Text gesucht und visuell aufbereitet.
Information Retrieval befasst sich mit der Suche nach relevanten Daten und Dokumenten in verschiedenen Quellen. Im Text Mining kann damit nicht nur die Ausgangsdatenbasis für den Prozess ermittelt werden, sondern findet auch Anwendung bei der Suche nach ergänzenden Informationen für erkannte Datenmuster oder Themen im Analyseprozess.
Information Extraction wird dazu verwendet, um nach Fakten in Textdokumenten zu suchen. Hierfür werden die Textdaten unter anderem mit Natural Language Processing (NLP) aufbereitet und annotiert. Die daraus resultierenden strukturierten Daten werden für die weitere Analyse benötigt.
Ablauf eines Text Mining-Prozesses
Ein typischer Ablauf eines Text Mining Prozesses umfasst die Schritte des Information Retrieval, der Information Extraction und des Data Mining. Die Abbildung zeigt einen groben schematischen Ablauf im Text Mining.
Die Ausgangsdatenbasis kann mittels Information Retrieval direkt aus Textdokumenten oder aus Web-Ressourcen stammen, bei letzterem ist eine aufwändigere Bereinigung der Daten notwendig (Markup entfernen). In der Vorverarbeitung werden die Textdaten unter anderem mit Verfahren der Information Extraction aufbereitet und für die weitere Verarbeitung vorbereitet.
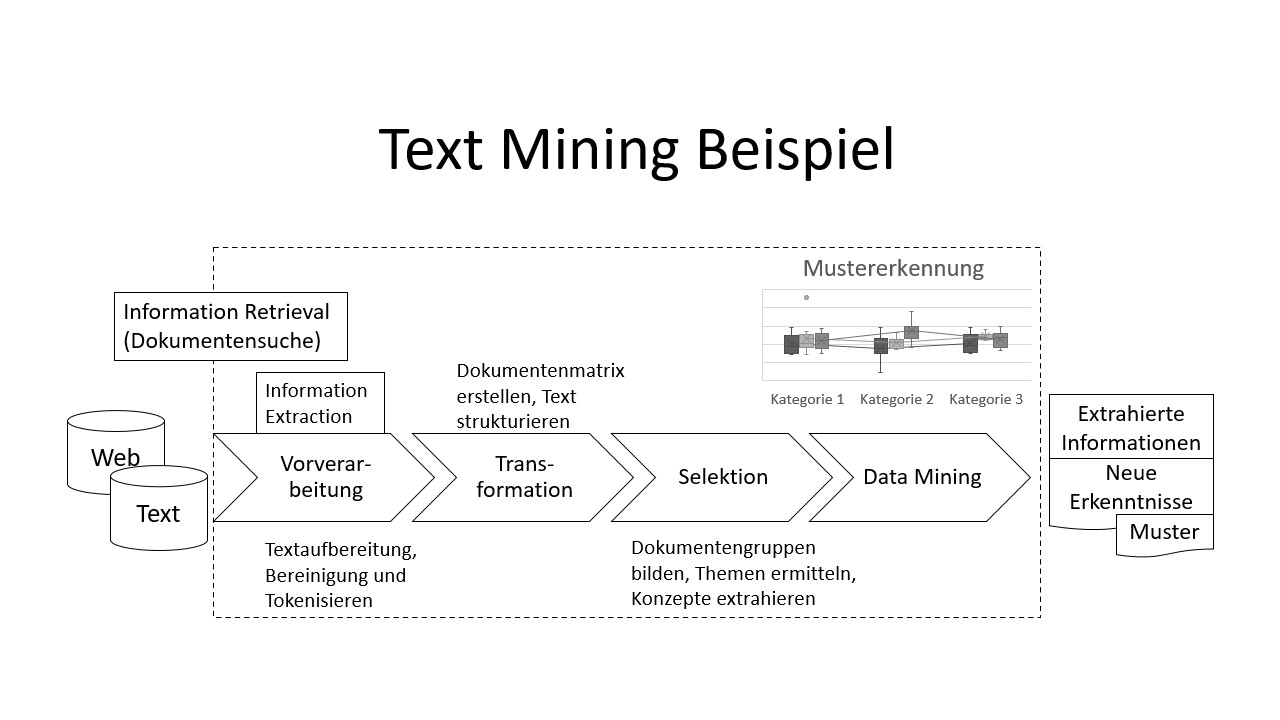
Um Textdaten analysieren zu können, müssen diese im zweiten Schritt in eine Dokumentenmatrix transformiert werden. Aus dieser können Vektoren erzeugt werden, mit denen Ähnlichkeiten berechnet werden. Dadurch lassen sich die Daten im dritten Schritt clustern oder klassifizieren, um Themen, Gruppierungen oder Muster in den Daten erkennen zu können.
Im letzten Schritt, dem Data Mining, werden die Daten analysiert und visuell aufbereitet. Die daraus gewonnen Erkenntnisse, Datenzusammenhänge oder Muster können anschließend für weitere Zwecke verwendet werden.
Text Mining - Vorteile und Nachteile
Text Mining - Vorteile von Text Mining
Die Vorteile von Text Mining können in verschiedenen Kontexten erheblich sein:
- Effizienzsteigerung: Automatisierte Textanalyse spart Zeit und Ressourcen im Vergleich zur manuellen Verarbeitung.
- Erkennung von Mustern: Komplexe Zusammenhänge und Trends können erkannt werden, die für menschliche Analysten schwer zugänglich wären.
- Vielfältige Anwendungen: Von Market Research über Kundenfeedback-Analysen bis hin zu medizinischen Diagnosen – die Einsatzmöglichkeiten sind breit gefächert.
- Skalierbarkeit: Text Mining kann große Datenmengen aus unterschiedlichsten Quellen verarbeiten, von sozialen Medien bis hin zu wissenschaftlichen Publikationen.
Text Mining - Nachteile von Text Mining
Trotz seiner Vorteile hat Text Mining auch Herausforderungen:
- Qualität der Daten: Unstrukturierte Daten können fehlerhaft oder uneinheitlich sein, was die Analyse erschwert.
- Kosten: Die Implementierung von Text Mining-Lösungen erfordert oft hohe Investitionen in Technologien und Fachwissen.
- Interpretationsprobleme: Ergebnisse können schwer verständlich oder missverständlich sein, insbesondere ohne fundierte Domänenkenntnisse.
- Datenschutzrisiken: Die Analyse sensibler Daten erfordert eine strenge Einhaltung von Datenschutzrichtlinien.
Einsatzbereiche von Text Mining
Text Mining kann zur automatisierten Aufbereitung von Textdokumenten verwendet werden. Dabei kann der Prozess direkt nach verwandten Themen oder relevanten Zusatzinformationen suchen und in das Ergebnis integrieren.
Ein Anwendungsbeispiel könnte die Suche nach medizinisch-wissenschaftlichen Erkenntnissen sein, bei dem zu einer Diagnose relevante Forschungsergebnisse und Behandlungsansätze automatisiert ermittelt und dem medizinischen Personal als Entscheidungshilfe bereitgestellt werden. Dieses Beispiel enthält Ansätze der künstlichen Intelligenz.
Ein weiterer Anwendungsbereich ist die Sentiment Analysis. Bei dieser wird die Einstellung oder Stimmung zu einem Text oder im Text vorhandenen Objekt (z. B. ein Produkt) ermittelt. Dadurch kann beispielsweise aus Kundenmeinungen oder Produktbewertungen Kritik und Lob ermittelt werden.
Text Mining - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Text Mining sollte man sich folgende Punkte merken:
- Das Text Mining ist ein Prozess zur Analyse von unstrukturierten Textdaten mit dem Ziel, Muster und relevante Informationen zu extrahieren.
- Es kombiniert Technologien aus der Linguistik, Datenwissenschaft und KI, um wertvolle Erkenntnisse zu gewinnen.
- Seine Anwendungen reichen von Kundenfeedback-Analysen bis hin zur medizinischen Forschung und bieten sowohl Chancen als auch Herausforderungen.