
Supervised Learning
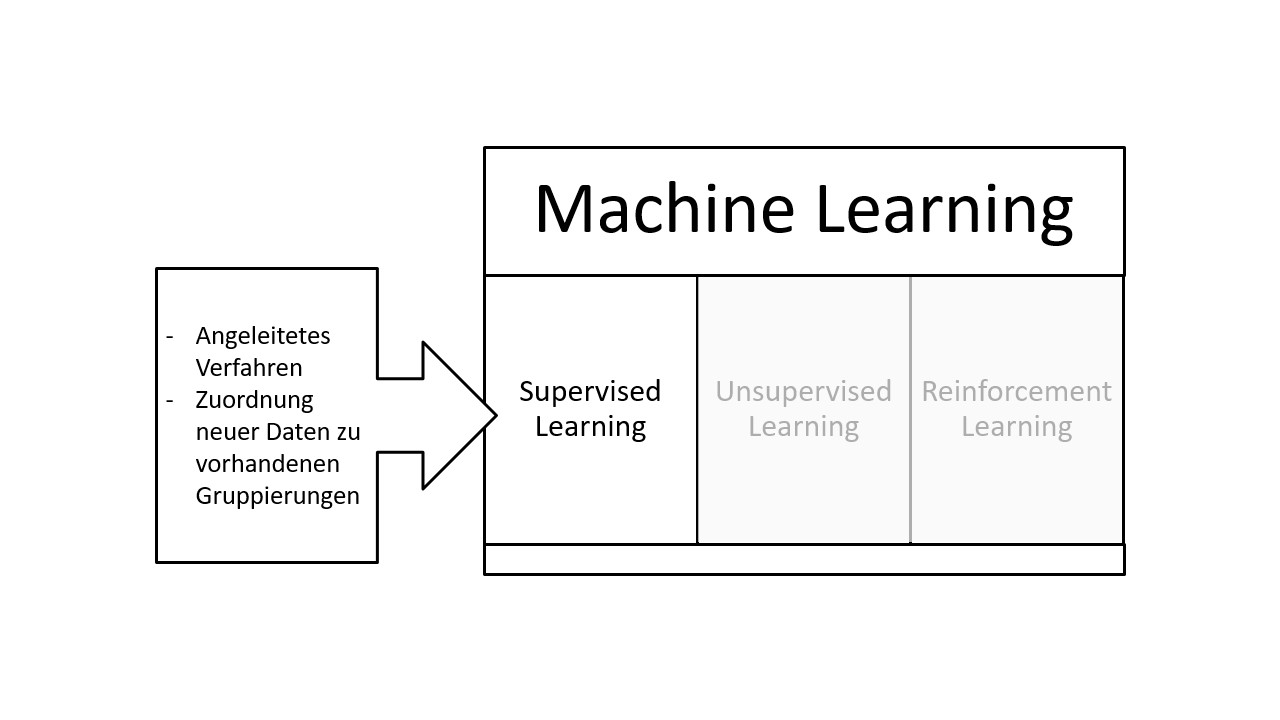
Das Supervised Learning, auch überwachtes Lernen genannt, stellt eines von drei Ansätzen des maschinellen Lernens, nachfolgend Machine Learning, dar.
Wie in der Abbildung ersichtlich, umfasst Machine Learning neben dem Supervised Learning auch das Unsupervised Learning sowie das Reinforcement Learning.
Das Supervised Learning ist ein angeleitetes Verfahren, bei dem Trainingsdaten mit annotierter Gruppenzugehörigkeit für den Aufbau des Modells bereitgestellt werden. Die Gruppeneinordnung neuer Daten, basiert auf einer statistischen Prognose.
Vorgehensweise im Supervised Learning-Verfahren
Das Supervised Learning hat zum Ziel, Daten einer Klasse oder Gruppierung zuzuordnen, die durch den Nutzenden vorgegeben sind, aber nicht jeder Datensatz manuell bewertet werden kann (z. B. Kreditbewilligung abhängig von Kredithöhe und Bonität). Die Kernaufgabe besteht darin, ein Modell mithilfe von Beispieldaten aufzubauen, das die Zuordnung anschließend selbstständig übernimmt.
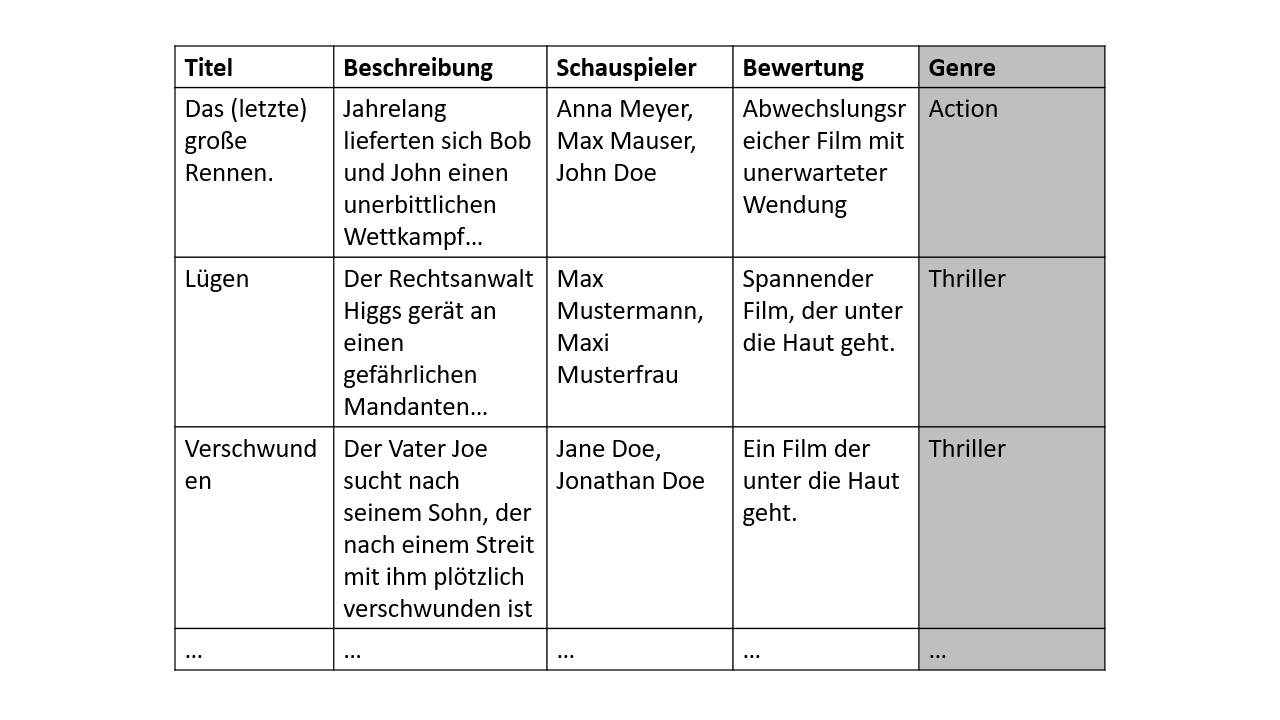
Die Beispieldaten enthalten unterschiedliche Features (Eigenschaften), die dazu führen, dass sie einer definierten Gruppe zugeordnet werden. Der Algorithmus zum Modellaufbau erhält während des Trainings einen Datenkorpus, der die zu gruppierenden Daten enthält sowie deren Zuordnung zu einer Gruppe. Verallgemeinert gesagt, lernt der Algorithmus daraus welche Feature zu welcher Gruppe gehören.
Die Abbildung stellt einen solchen Datenkorpus dar. Die Spalten Titel, Beschreibung, Schauspieler und Bewertung werden als Feature bezeichnet. Das Genre ist der Zielwert, der in der Trainingsphase vorgeben ist und später ermittelt werden muss. Die Genreausprägungen stellen die Gruppen dar (hier Action und Thriller), die es geben kann.
Die Zugehörigkeit neuer, unbekannter Daten wird dann auf Basis des trainierten Modells geschätzt. Je besser das Modell ist, desto zuverlässiger ist die Schätzung.
Der Vorteil des Supervised Learning besteht darin, dass es Algorithmen verwendet, die auch bei kleinen Datenmengen, zu guten Ergebnissen führen können.
Algorithmen für Supervised Learning-Verfahren
Für das Supervised Learning können Regressions- und Klassifikationsverfahren verwendet werden. Im Falle einer Regression wird ein Trend in den Gruppen der Modelldaten ermittelt. Typische Regressionen sind die Linear Regression und die Random Forest Regression.
Bei einer Klassifikation wird ein Datensatz einer Gruppe zugeordnet. Für Klassifikationen verwendet man beispielsweise die Support Vector Machine (SVM) oder den Naive Bayes Klassifikator.
Einsatzbereiche für Supervised Learning
Supervised Learning kann dazu verwenden werden Empfehlungen (Recommendations) zu generieren, die klassischerweise bei Filmtiteln, Produkten oder in sozialen Netzwerken Anwendung finden. Hierbei werden Feature von Artikeln (z. B. Farbe), Filmtiteln (z. B. Genre) und anderen Mitglieder eines Netzwerkes (z. B. Beruf) mit den Daten des Nutzenden verglichen.
Darüber hinaus kommt es bei der automatischen Klassifizierung von Texten zum Einsatz, wobei diese einem Thema (z. B. Wirtschaft) zugeordnet werden. In der Bilderkennung ist der Ansatz ebenfalls zu finden, um beispielsweise eine Verschlagwortung des Bildinhaltes zu generieren (z. B. Katze, Tisch).
Supervised Learning - Vorteile und Nachteile
Supervised Learning - Vorteile von Supervised Learning
Supervised Learning bietet zahlreiche Vorteile:
- Präzision: Modelle können sehr genaue Vorhersagen treffen, wenn die Trainingsdaten qualitativ hochwertig sind.
- Vielseitigkeit: Es ist in vielen Bereichen einsetzbar, von Gesundheitswesen bis zur Finanzwelt.
- Klare Struktur: Dank der definierten Labels ist der Trainingsprozess leicht nachvollziehbar.
Supervised Learning - Nachteile von Supervised Learning
- Hoher Datenbedarf: Es benötigt große Mengen an beschrifteten Daten, was zeit- und kostenaufwendig sein kann.
- Überanpassung: Modelle können die Trainingsdaten zu spezifisch lernen und bei neuen Daten schlecht abschneiden.
- Begrenzte Flexibilität: Die Leistung hängt stark von der Qualität und der Vielfalt der Trainingsdaten ab.
Supervised Learning - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Supervised Learning sollte man sich folgende Punkte merken:
- Supervised Learning nutzt beschriftete Daten, um präzise Vorhersagen zu treffen.
- Es wird in Regression und Klassifikation unterteilt.
- Die Qualität der Ergebnisse hängt stark von den verfügbaren Daten ab.
