
Cross Industry Standard Process for Data Mining
Der Begriff CRISP-DM steht für Cross Industry Standard Process for Data Mining und ist ein 1996 entwickeltes Standardmodell für den Einsatz von Data Mining in branchenübergreifenden Anwendungsbereichen.
Die Entwicklung des Vorgehensmodell wurde von der Europäischen Union gefördert und seitens großer Konzerne konzipiert und implementiert.
In 2015 wurde ein erweitertes und verfeinertes Prozessmodell von CRISP durch IBM unter dem Namen ASUM-DM (Analytics Solutions Unified Method) veröffentlicht.
CRISP-DM - Einsatzgebiet und Merkmale
Das CRISP-DM unterteilt einen Data Mining Prozess in die sechs Phasen Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation und Deployment.
Dadurch soll eine einheitliche Vorgehensweise bei der Entwicklung von Data Mining Prozessen erreicht werden. Durch den Branchen-neutralen Ansatz kann CRISP-DM, kann das Vorgehensmodell in allen Data Mining Projekten eingesetzt werden.
Die detaillierte Umsetzung des Modells erfolgt dann jeweils Tool- und Branchen-spezifisch. Die wesentlichen Merkmale des CRISP-DM-Standards sind:
- von der EU gefördert
- von namhaften Unternehmen erarbeitet (über 200 Mitglieder in der CRISP-DM Special Interest Group)
- als Industriestandard konzipiert
- offener weltweit nutzbarer Standard
CRISP-DM - Prozessmodell im Detail
In der Abbildung ist das CRISP-DM Prozessmodell zu sehen. Es stellt einen iterativen Ansatz zur Durchführung von Data Mining Projekten dar und beschreibt den Wechsel zwischen den Phasen, die je nach Zwischenergebnis zu einer der vorhergehenden Phase zurückführt (z.B. Modeling zurück zu Data Preparation) oder den Prozess fortsetzt (z.B. Data Understanding zu Data Preparation).
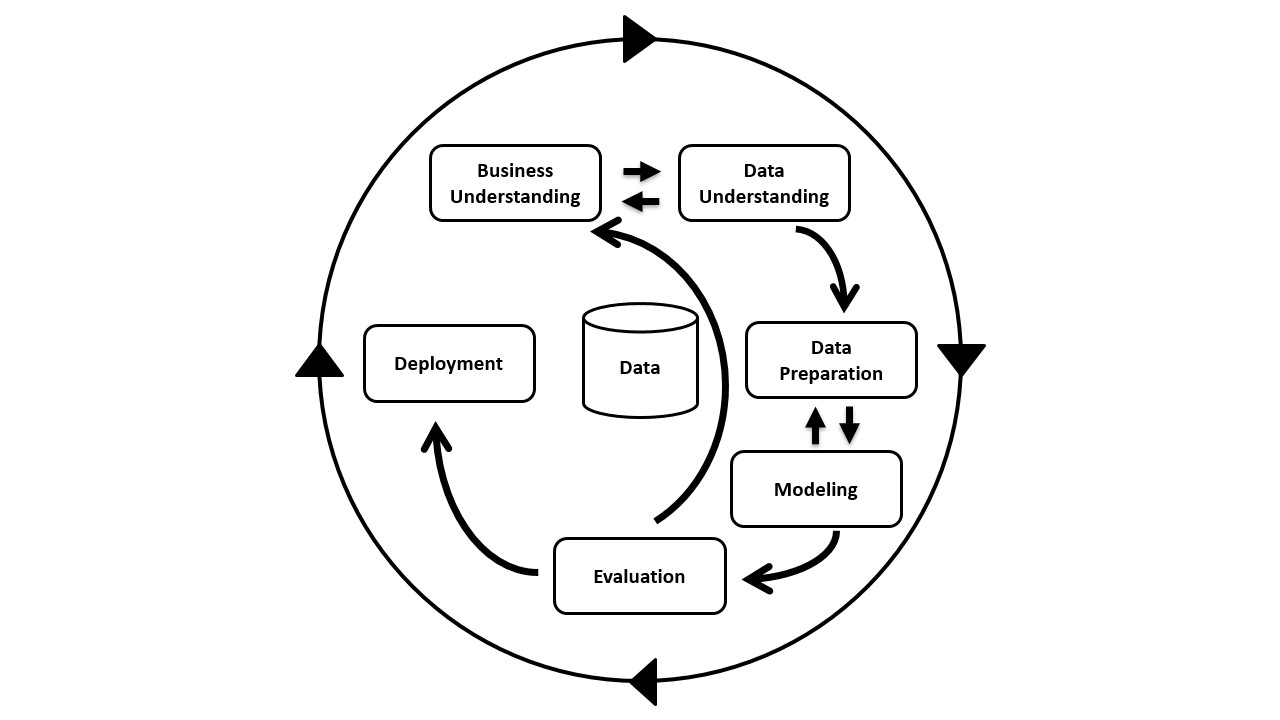
Business Understanding - Geschäftsverständnis
In der ersten Phase geht es um die Festlegung der Ziele und Anforderungen für das Data Mining Projekt. Nur wenn klar ist, welches Ziel und welchen Nutzen das Data Mining verfolgen bzw. erbringen soll, kann ein Ansatz entwickelt werden. Als Ergebnis dieser Phase steht eine konkrete Aufgabenstellung und die grobe Vorgehensweise für das Projekt fest.
Data Understanding - Datenverständnis
In der zweiten Phase wird die verfügbare Datensammlung analysiert, um sich einen Überblick über deren inhaltliche Aussagekraft und Qualität zu verschaffen. Dadurch kann festgestellt werden, ob die Daten und deren Qualität für die festgelegten Ziele ausreichen. Ist dies nicht der Fall, müssen die Ziele aus der vorangegangenen Phase angepasst oder neue geeignete Datenquellen aufgetan werden.
Data Preparation - Datenaufbereitung und -vorbereitung
In der dritten Phase werden die zur Zielerreichung geeigneten Daten aufbereitet und für die weiteren Schritte als Datensatz vorbereitet. Die Aufbereitung umfassen die Bereinigung und das Vervollständigen von Daten. Der finalen Datensatzes wird für die Modellierung bereitgestellt.
Modeling - Modellierung
In der vierten Phase, der Modellierung, werden zur Lösung der Aufgabenstellung geeignete Data Mining-Methoden angewandt, um Modelle zu erstellen. Dabei findet eine Optimierung der relevanten Parameter statt. In der Regel werden mehrerer Modelle erstellt und anschließend gegeneinander evaluiert.
Evaluation - Evaluierung der Modelle
Die Evaluierung der erstellten Modelle erfolgt in Phase fünf. Hier wird geprüft, welches der ermittelten Modelle die Aufgabenstellung am besten lösen kann. Hierfür ist ein sorgfältiger Abgleich der Modellergebnisse mit der Aufgabenstellung notwendig.
Deployment - Bereitstellung der Modelle und Analysen
Die abschließende sechste Phase dient der Aufbereitung und Präsentation der Analyseergebnisse. Die gewonnenen Einsichten können als Analyseprozesse aufbereitet oder als Entscheidungsmodelle in einen Entscheidungsprozess integriert werden. Die Art des Deployment hängt von der ursprünglichen Ziel- und Aufgabenstellung ab.
CRISP-DM - Ziele (fachlich & technisch)
Die Ziele von CRISP-DM sind, kurz zusammengefasst, folgende:
- Bereitstellung eines einheitlichen Prozessmodells für das Data Mining
- Anwendungs- und Herstellerneutralität
- branchenübergreifende Nutzung
- Bereitstellung einer Schritt-für-Schritt Anleitung für das Data Mining
CRISP-DM - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag CRISP-DM sollte man sich folgende Punkte merken:
- Der Fachbegriff CRISP-DM steht für Cross Industry Standard Process for Data Mining und ist ein 1996 entwickeltes Standardmodell für den Einsatz von Data Mining in branchenübergreifenden Anwendungsbereichen.
- Das CRISP-DM unterteilt einen Data Mining Prozess in die sechs Phasen Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation und Deployment.
- Die Entwicklung des CRISP-DM Vorgehensmodells wurde von der Europäischen Union gefördert und seitens großer Konzerne konzipiert und implementiert.
