
Apache Hadoop
Das auf Java basierende Open Source Framework Apache Hadoop kann als eine Art Ökosystem verstanden werden, in dem verschiedene eigene und fremde Komponenten und Module verknüpft werden können, um große Datenmengen (im Petabyte-Bereich) verarbeiten zu können.
Das Apache Hadoop Framework setzt dabei auf verteilte Komponenten und ist sehr gut skalierbar. Bei der Verarbeitung kommt häufig die Lambda-Architektur zum Einsatz.
Apache Hadoop gehört seit 2008 zu den Top-Level-Projekten der Apache Foundation und geht auf den Entwickler Doug Cutting zurück. Es basiert auf Googles Map-Reduce-Algorithmus zur verteilten Berechnung großer Datenmengen auf spezialisierten Computerclustern. Im Laufe der letzten Jahre wurden zahlreiche Erweiterungen und Algorithmen entwickelt, die auf Hadoop aufsetzen oder dedizierte Funktionen zur Verfügung stellen.
Zentrale Module des Apache Hadoop Frameworks
Das Hadoop Common stellt das Basismodul mit vielen Grundfunktionen und Werkzeugen dar. Über Schnittstellen wird die Kommunikation mit Dateisystemen und innerhalb der verteilten Cluster sichergestellt.
Die verteilte Verarbeitung und Speicherung von Daten ermöglicht das Modul Hadoop Distributed File System (HDFS). Das HDFS ist ein Dateisystem, das große Dateien in Datenblöcke fester Länge zerlegt und in redundanter Form auf die Speicherknoten im Cluster legt. Ein Cluster besteht aus einer Vielzahl an Knoten, die sich in Master- und Slave-Knoten unterteilen lassen. Der Master-Knoten, auch NamedNode genannt, verwaltet die Knoten eines Clusters in dem es Datenanfragen entgegennimmt und die Speicherung auf den Slave-Knoten organisiert sowie die Verwaltung der Metadaten übernimmt.
Der MapReduce-Algorithmus ist ein zentraler Bestandteil des Hadoop Frameworks. Das Modul ermöglicht die Aufteilung komplexer Datenverarbeitungsprozesse in viele kleine Aufgaben, die parallel von verschiedenen Knoten verarbeitet werden können. Dadurch entsteht eine hohe Verarbeitungsgeschwindigkeit. Die einzelnen Teilergebnisse werden vom Algorithmus selbstständig wieder zusammengeführt und bereitgestellt.
Das Hadoop YARN (Yet Another Resource Negotiator) Framework dient der Ressourcen-Verwaltung innerhalb eines Clusters. Es wird im Zusammenspiel mit dem MapReduce Algorithmus genutzt, um die Teilaufgaben dynamisch den Clustern entsprechend ihrer Auslastung zuzuweisen.
Aufbau und Ablauf einer verteilten Datenverarbeitung
Nachdem die Datenanfrage an Hadoop übermittelt wurde, startet der MapReduce-Algorithmus und zerlegt die übermittelten Daten in einzelne Aufgabenpakte. Diese sind parallel ausführbar und werden mittels YARN auf die Clusterknoten verteilt. Die Abbildung zeigt den schematischen Aufbau eines solchen Clusters. Der Master-Knoten verteilt die Datenblöcke auf die verschiedenen Slave-Knoten und sorgt für deren Replikation im Verbund, um im Falle eines Knotenausfalls oder Datenverlustes die verlorenen Datenblöcke aus einem Replikat wieder herzustellen.
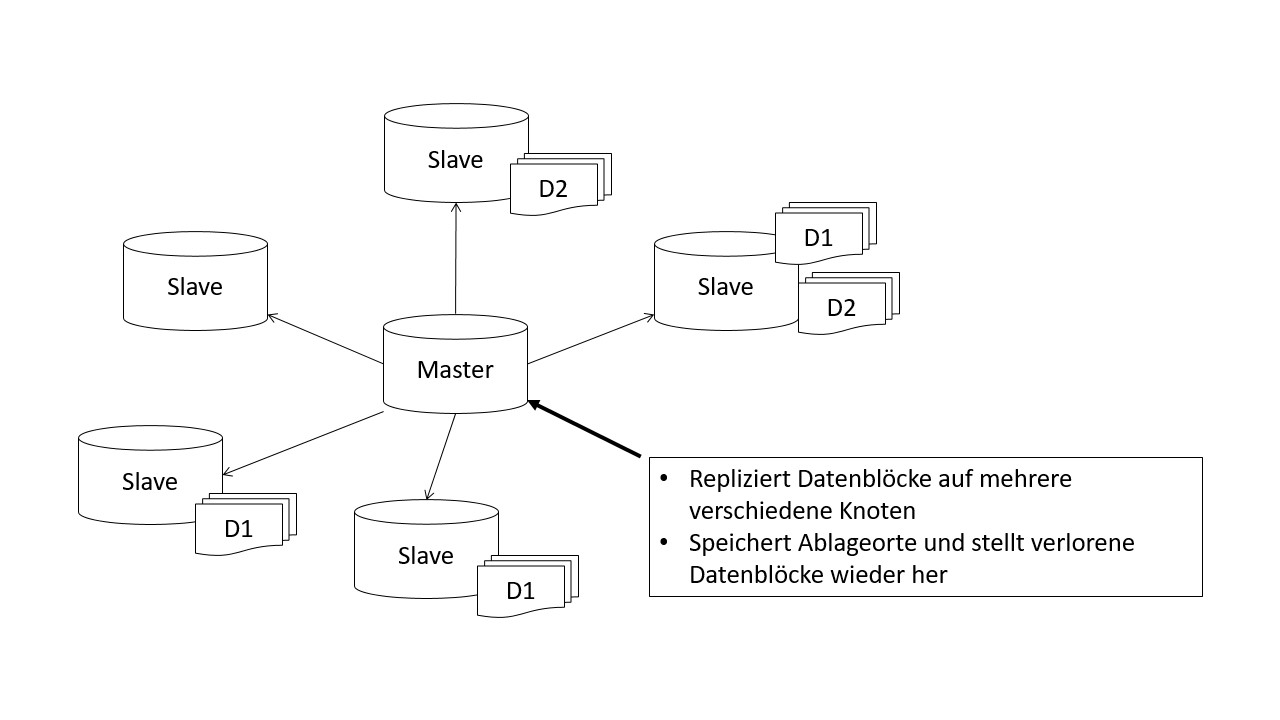
Nach Abschluss der Berechnung werden die Teilaufgaben zusammengefügt und zur weiteren Verarbeitung bereitgestellt oder gespeichert. Für die parallele Ausführbarkeit der Teilaufgaben sorgt der MapReduce-Algorithmus.
Einsatzbereiche von Apache Hadoop
Die Eigenschaft große Datenmengen mit hoher Geschwindigkeit verarbeiten und speichern zu können, macht es für die Entwicklung von Big Data oder Data Warehouse Anwendungen attraktiv. Durch die Erweiterungen HBase und Hive stehen SQL Schnittstellen zur Verfügung, die eine klassische Entwicklung von Datenverarbeitungsprozessen, wie es im Business Intelligence Bereich typisch ist, ermöglichen.
Mit dem kompatiblen Apache Spark Framework werden Machine Learning-Verfahren zugänglich und können direkt im Hadoop-Umfeld entwickelt werden.
Apache Hadoop - Definition & Erklärung - Zusammenfassung
Im Zusammenhang mit dem Lexikoneintrag Apache Hadoop sollte man sich folgende Punkte merken:
- Das auf Java basierende Open Source Framework Apache Hadoop kann als eine Art Ökosystem verstanden werden, in dem verschiedene eigene und fremde Komponenten und Module verknüpft werden können, um große Datenmengen (im Petabyte-Bereich) verarbeiten zu können.
- Das Apache Hadoop Framework setzt dabei auf verteilte Komponenten und ist sehr gut skalierbar.
- Apache Hadoop gehört seit 2008 zu den Top-Level-Projekten der Apache Foundation und geht auf den Entwickler Doug Cutting zurück.
