
ETL - Was ist ein ETL-Prozess?
Die Abkürzung ETL steht für Extraktion (Extract), Transformation (Transform) und Laden (Load) und ist ein Datentransformationsprozess, speziell im Data Warehouse-Umfeld.Der Begriff ETL findet sich auch in anderen Bereichen des Software-Einsatzes z. B. bei Self Service BI-Lösungen wieder, hat aber mit den Konzepten und der Architektur eines Data Warehouse nichts zu tun.
Lediglich der Prozess der Datenverarbeitung und -bereitstellung beruht auf den gleichen Prinzipien.
Transformationsprozess von Daten im DWH
Es gibt in der Praxis verschiedene Sichtweisen auf den ETL-Vorgang im Data Warehouse. Diese Sicht hat mit der Architektur des Systems zu tun. Ein DWH kann drei- oder vierschichtig aufgebaut werden. Entsprechend verlagert sich hier der Verarbeitungsschritt Transformation in die Cleanse-Schicht und die Extraktion wird in der Stage-Schicht zunächst vorgehalten.
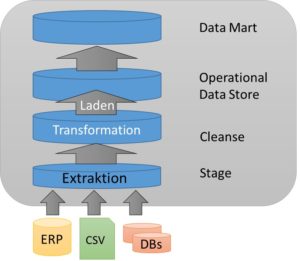 Die Extraktion stellt den ersten Schritt des Datenverarbeitungsprozesses dar. In diesem werden aus den Quellsystemen oder -dokumenten Daten extrahiert, also herausgezogen, und für die weiteren Bearbeitungsschritte in der Eingangsschicht des DWHs bereitgestellt. Dabei können auch nur Teilaspekte der Quelldaten verwendet werden. Alle nicht benötigten Daten, werden nicht extrahiert.
Die Extraktion stellt den ersten Schritt des Datenverarbeitungsprozesses dar. In diesem werden aus den Quellsystemen oder -dokumenten Daten extrahiert, also herausgezogen, und für die weiteren Bearbeitungsschritte in der Eingangsschicht des DWHs bereitgestellt. Dabei können auch nur Teilaspekte der Quelldaten verwendet werden. Alle nicht benötigten Daten, werden nicht extrahiert.
Im zweiten Schritt erfolgt die Transformation der Daten in der Stage- oder Cleanse-Schicht. In dieser werden die Quelldatentypen in die Spaltentypen der Zieltabellen umgewandelt. Zudem erfolgt eine inhaltliche Überprüfung der Daten. Dadurch werden bspw. Duplikate ermittelt und herausgefiltert, Berechnungen durchgeführt oder zusätzliche (Stamm-)Daten verknüpft.
Im dritten Schritt werden die Daten in das Data Warehouse geladen. Dort werden die sie strukturiert und normalisiert gespeichert. Ein Teil der Daten wird zudem historisiert, um Änderungen über einen Zeitverlauf nachvollziehbar und auswertbar zu machen.
Von ETL zu ELT
Bei der Datenverarbeitung können die Schritte Transformation und Laden auch vertauscht werden. In diesem Fall werden die Daten zunächst in eine zentrale Datenbank geladen und anschließend mit speziellen Algorithmen transformiert.
Besonders im Big Data-Umfeld ist diese Vorgehensweise zu finden, da in diesem Fall Daten zunächst gesammelt werden, um diese für Auswertungen bereitzustellen. Spezielle Prozesse zur normalisierten Speicherung, wie in einem klassischen Data Warehouse, sind hier nicht vorgesehen.